

学者提出:FPGA作为加速器来解决GPU负载过大的问题。
在当今社会,人工智能和机器学习领域的研究已经取得了显著成就。现有的一些研究表明神经网络在这些领域相比传统算法的性能更好。然而,在自然语言处理领域,对机器来说,理解、学习人类语言仍然是一件很困难的事情,这成为一个比较有挑战性的问题 。研究者提出了很多模型来解决这个问题,因此许多学者采取FPGA作为加速器来解决GPU负载过大的问题。
FPGA作为数据处理硬件加速器
在机器视觉与人工智能的嵌入式应用场景中,需要完成大量的数据计算分析。对于复杂算法,采用CPU的实现方式普遍存在效率低下,实时性较差的缺点;采用GPU的实现的方式则会导致功耗和成本的增加。于是,越来越多的研究采取FPGA作为数据处理硬件加速器。
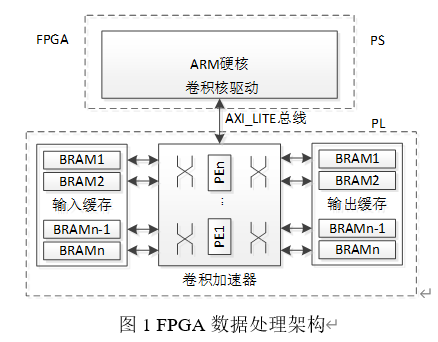
由于卷积神经网络在图像、语音识别方面表现出的良好学习特征,很多研究人员欲将其引入人工智能的嵌入式领域。CNN除了具有多层学习能力,还自带并发计算特征[2],恰好与FPGA的并发处理相互照应。同时,FPGA具有的可编程能力能够有效适应CNN的网络变化。但是,经典CNN的结构和参数过于复杂,对于资源受限的嵌入式系统而言,难以直接进行使用。
论文设计了一种卷积网络加速器,通过对各层的优化来改善网络的收敛性和适应性,以及神经元增长对权值处理效率的影响。针对FPGA应用设计了相应的加速器实现架构,包括数据处理和缓存机制,并通过资源分析来调整网络架构。最后,利用与不同平台与不同加速器的比较,对基于卷积网络加速器的FPGA数据处理性能进行验证。
CONTENT END


